Featured Posts

Machine_Learning

TFX 머신러닝 파이프라인 사용하기
팀에서 필요한 학습 파이프라인 구축하기
핑퐁팀에서는 루다의 대화 성능을 지속적으로 발전시키기 위해 Continual Learning을 연구하고 있어요. 이를 위해 새로운 데이터를 받으면 모델을 학습하고, 평가하는 일련의 과정을 수행해야 하는데, 이 모든 과정에 사람이 직접 개입하는 것은 너무 효율적이지 않았어요. 그래서 반복되는...

VPT: 다이아몬드 곡괭이를 만들기 위한 여정
OpenAI에서 어떻게 다이아몬드 곡괭이를 만들었는지 알아봅니다. (VPT)

AWS Inferentia를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 2탄
우당탕탕 Inferentia 배포하기
지난 글에서는 AWS Inferentia 소개와 사용법, GPU와의 성능 비교 등을 설명해 드렸어요! 이번 글에서는 Inferentia를 실제 서비스에 도입하기 위해 핑퐁팀에서 어떤 과정들을 거쳤는지 소개해드릴게요.😋 preview ...
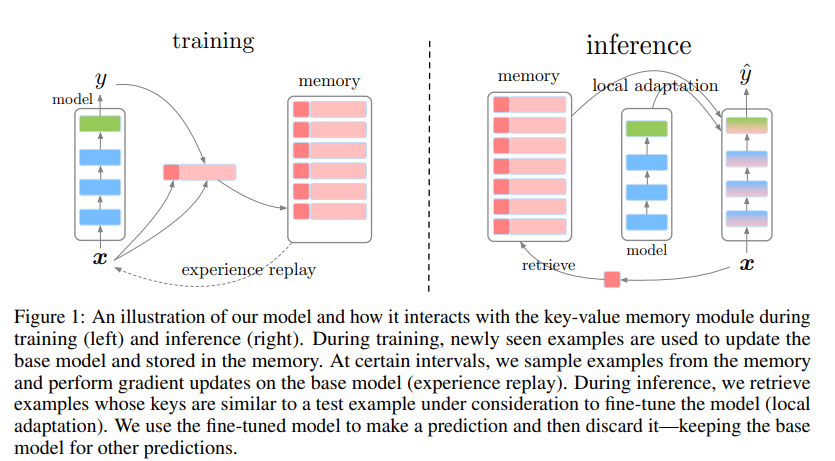
Continual Learning: 꾸준히 성장하는 모델을 만들기 위한 기술
주제별로 알아보는 continual learning
Continual Learning은 지속적으로 들어오는 데이터 스트림을 학습하기 위한 방법입니다. 데이터가 지속적으로 주어짐에 따라 데이터의 분포 혹은 데이터가 다루는 태스크가 변화하고, 모델은 현재 주어진 데이터를 학습할 때 기존에 배운 지식을 일부 잃기 마련입니다. 이러한 현상을 Catastrophic Forgetting이라고...
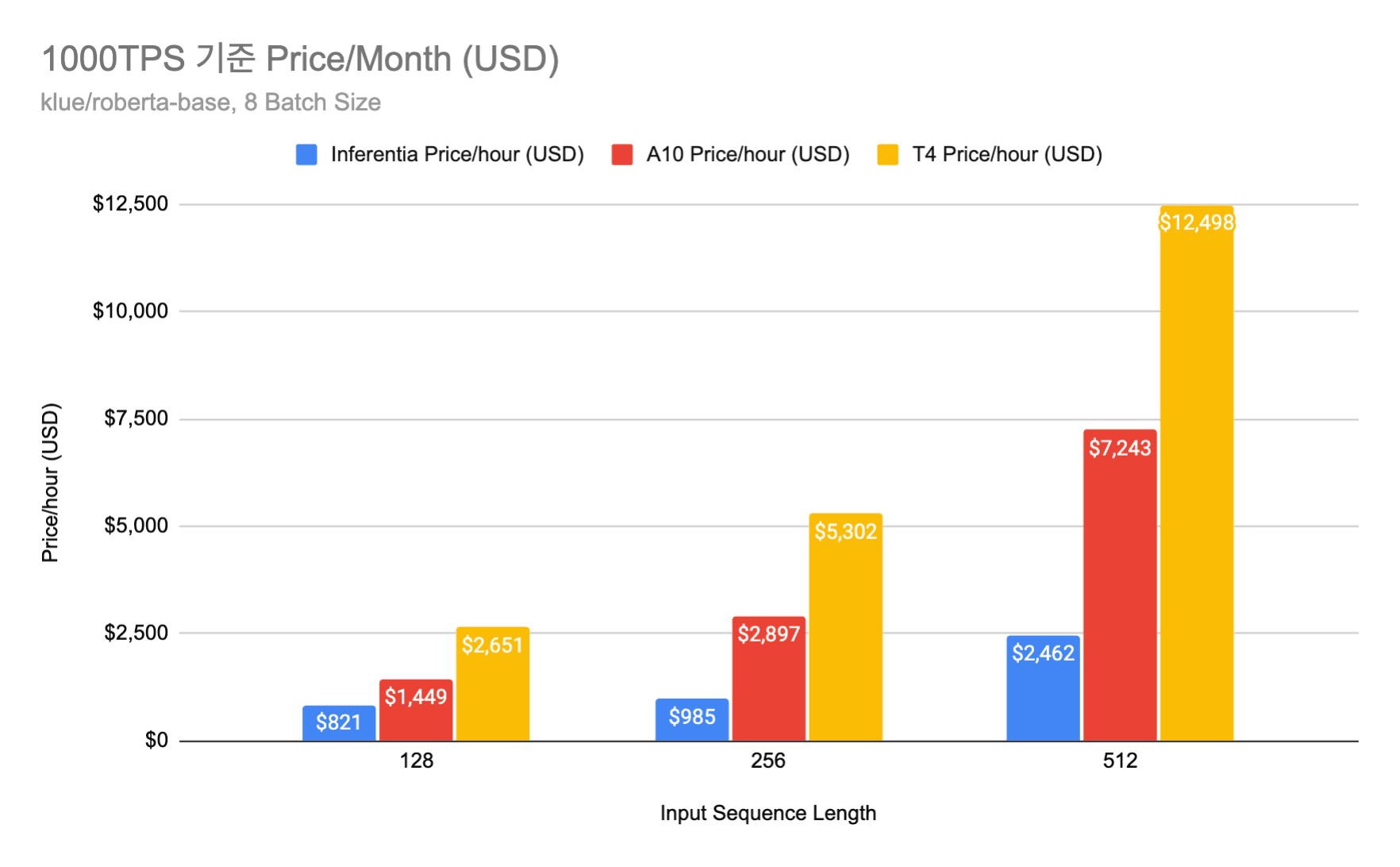
AWS Inferentia 를 이용한 모델 서빙 비용 최적화: 모델 서버 비용 2배 줄이기 1탄
AWS 고객감사 특별 할인... 모델 서빙 비용 최대 80% 초특가 할인전
머신러닝 엔지니어링(MLE)팀에서는 제품에 사용되는 여러 딥러닝 모델을 최대한 낮은 지연 시간과 적은 비용으로 서빙하기 위해서 여러 하드웨어 및 소프트웨어 최적화 기법을 실험해보고 실제 프로덕트에 적용하고 있습니다. 높은 수준으로 최적화된 모델 서빙은 실제 서비스에서 더 큰...

ACL 2022 Review
핑퐁팀과 함께하는 ACL 2022 Review
올해로 60회를 맞은 Annual Meeting of the Association for Computational Linguistics (ACL)는 자연어 처리 분야 최고의 국제 컨퍼런스로서 최신 NLP 연구들이 발표되는 행사입니다. 엔데믹 상황으로 접어들면서 올해 ACL은 오프라인과 온라인에서 동시에 하이브리드 형태로 진행되었습니다. 저희 핑퐁팀의 이성현님,...
Apache Beam으로 머신러닝 데이터 파이프라인 구축하기 2편 - 개발 및 최적화
대규모 머신러닝 데이터 파이프라인 개발하고 최적화하기
지난 글에서는 핑퐁팀이 어떻게 Apache Beam을 도입하였는지를 설명드렸어요! 이번 글에서는 본격적으로 유지보수성을 높이면서 어떻게 머신러닝 데이터 파이프라인을 개발하였는지 차근차근 설명해 드릴게요. 😄 ...
Apache Beam으로 머신러닝 데이터 파이프라인 구축하기 1편 - 도입과 사용
빠르고 효율적인 병렬 데이터 파이프라인 도입기
핑퐁팀은 Apache Beam을 사용하여 사용자 데이터의 가명처리, 대규모 데이터 정제, 임베딩 벡터를 사용한 데이터 샘플링과 TFRecord 변환에 이르는 다양한 작업을 처리하고 있습니다. 핑퐁팀이 왜 Apache Beam을 사용하는지, 어떻게 사용하는지 자세하게 소개해볼게요. ...

알라꿍달라꿍의 대화요약 이모저모
2021 한국어 인공지능 자연어 경진대회 대화요약 수상기
저(박상준), 최기원, 오혜린 셋은 작년에 열렸던 2021 한국어 음성·자연어 인공지능 경진대회에 함께 팀을 이뤄 대화요약 부문에 참가했습니다. 회사에서 공식적으로 참가한 건 아니지만 자주 보면서 이야기를 나눠야 하다 보니 자연스레 회사 동료들과 함께 참가하게 되었습니다. 대회...

TensorFlow Custom Op으로 데이터 변환 최적화하기
4.697ms → 17.147μs
핑퐁팀에서는 모델 학습의 효율성을 위해 자주 TFRecord를 생성합니다. 하지만 정제할 데이터가 많은 경우에는 변환이 느려지고, 속도 최적화가 필요합니다. 이 때의 병목점을 Custom Op으로 교체하면 처리 속도를 매우 빠르게 만들 수 있습니다. 실제로 이번 최적화를 통해 한...